

- Googleの革新技術「TurboQuant」がKVキャッシュを3ビットに圧縮し、LLM推論速度を最大8倍に向上。
- メモリ消費を大幅に抑えることで、同一GPUでより長いコンテキスト処理と高スループットを実現。
- ハードウェア増強ではなくアルゴリズム最適化により、AI運用のコスト効率と拡張性を劇的に改善。
- 🚀 Googleの最新技術「TurboQuant」は、KVキャッシュを3ビットに圧縮し推論を劇的に高速化する。
- 🚀 メモリ使用量を大幅に削減し、LLMの応答速度を最大8倍まで引き上げる潜在能力を持つ。
- 🚀 長文コンテキストの処理能力を維持しつつ、コスト効率を劇的に改善する未来が開かれた。
生成AIの進化速度は留まることを知りません。毎日新しいモデルやライブラリが発表される中で、エンジニアや企業が直面している最大の実務課題は、モデルの性能向上そのもの以上に「推論コスト」と「レイテンシ(遅延)」です。特に長い文章を読み込ませる「長文脈(ロングコンテキスト)」処理においては、GPUメモリが瞬く間に枯渇してしまいます。
このボトルネックを打開する切り札として、Googleの研究チームが発表したのが「TurboQuant」です。単なるモデルの量子化(重みのビット数を減らす技術)を超え、推論時に生成される中間データを徹底的に圧縮することで、推論効率を限界まで高めるこの技術は、LLM活用の歴史におけるターニングポイントになるでしょう。

なぜ「KVキャッシュ」がLLMの足かせなのか?
現在の主流なLLM(Transformerアーキテクチャ)において、推論速度とメモリ効率を決定づけるのがKVキャッシュ(Key-Value Cache)です。これは、過去の対話内容や文脈を一度計算した後にメモリ上に保存し、次回の生成時に再計算を避けるための「記憶領域」です。
コンテキストウィンドウが128kトークン、あるいはそれ以上に拡大する現在、このKVキャッシュはGPUメモリを猛烈に消費します。メモリ容量が不足すると、推論速度は急激に低下し、最悪の場合はシステムが停止します。これまでvLLMなどのライブラリが「PagedAttention」を用いてメモリ管理を最適化してきましたが、TurboQuantは「データそのものを極限まで圧縮する」というアプローチで、インフラレベルのボトルネックを物理的に解決しようとしています。
従来のモデル量子化は、ニューラルネットワークの「重み(Weight)」を16bitから4bitや8bitへ落とす静的な手法が主流でした。一方、TurboQuantが対象とするKVキャッシュ圧縮は、推論という「動的なプロセス」の中で刻々と生成される中間値を3bitまで圧縮する動的な最適化技術であり、メモリ帯域幅の負荷を劇的に軽減する点が決定的に異なります。
「8倍」の高速化がもたらす破壊的なインパクト
TurboQuantの最大の驚きは、3ビットという極めて低い精度への圧縮にもかかわらず、精度の劣化を最小限に留めている点です。精緻なキャリブレーションと補正アルゴリズムにより、従来手法と比較して推論速度を最大8倍まで引き上げることに成功しました。
この「8倍」という数字がビジネスにもたらす価値は甚大です。例えば、これまで1つのGPUインスタンスで同時に3件のリクエストしか捌けなかったシステムが、理論上はさらに多くのユーザーを同時にサポートできるようになります。応答速度が劇的に向上することで、ユーザー体験(UX)は飛躍的に改善され、複雑な長文解析ツールやリアルタイムAIエージェントの構築が飛躍的に現実味を帯びてきます。
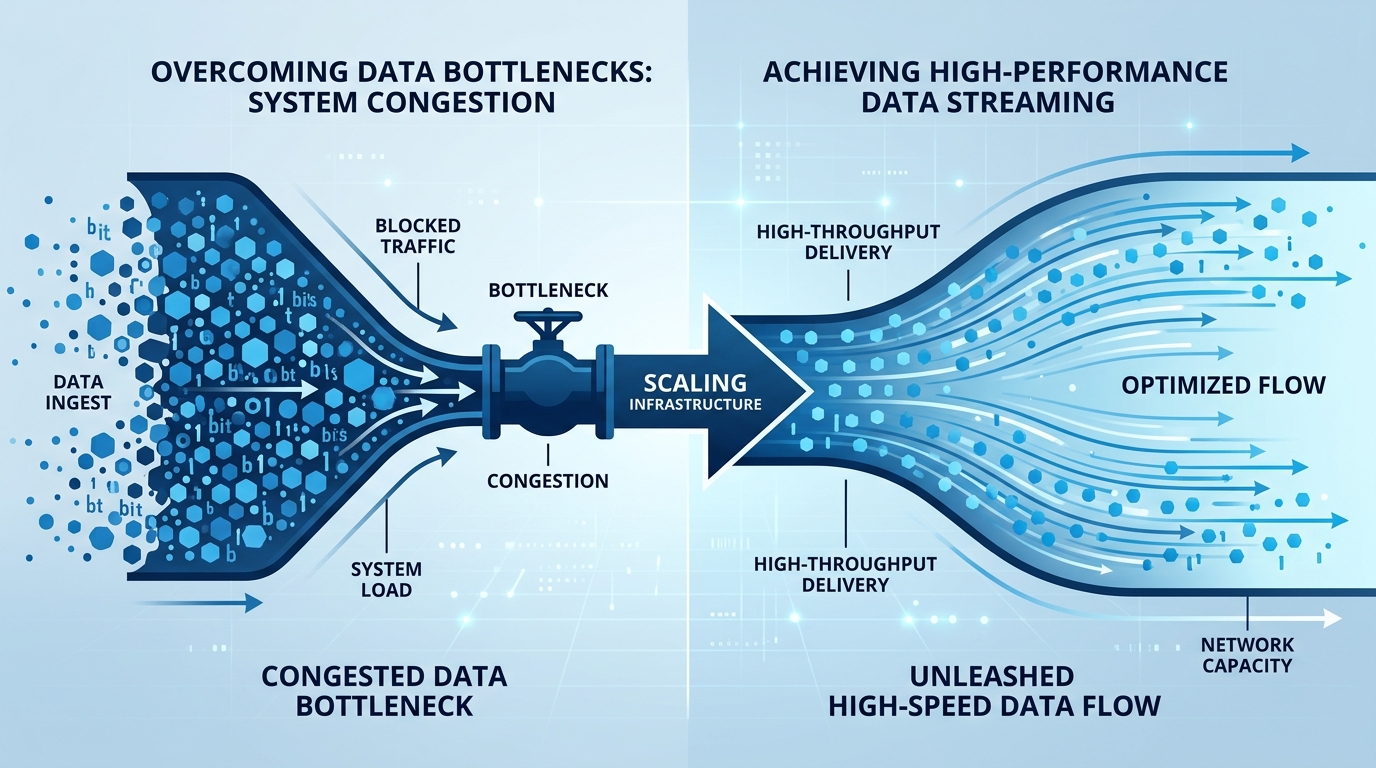
次世代のインフラ:PagedAttentionからTurboQuantへ
これまでに普及してきたPagedAttentionやvLLMといった技術は、メモリの断片化を防ぐ「メモリ管理の達人」でした。しかし、TurboQuantはこの層の上に、さらに「情報の密度を上げる」という新たなレイヤーを加えるものです。
もしあなたが現在、推論エンジンにvLLMを使用しているなら、TurboQuantを統合したアーキテクチャへの移行は、計算リソースを最大化するための必須ステップとなるでしょう。ハードウェアのスペックを買い足すのではなく、ソフトウェアのアルゴリズムでリソースを絞り出す。この「高密度な推論クラスター」を構築できる技術力こそが、これからのAI時代における企業の競争優位性になります。
TurboQuantの導入により、単に高速化するだけでなく、メモリを節約できるため「より大きなモデル」や「より長いプロンプト」を同じハードウェアで扱えるようになります。結果として、GPUインスタンスのコストを抑えつつ、モデルの知能を高めることが可能になるのです。
Nexistix的考察:AI運用の未来図
TurboQuantの登場により、LLMの運用現場は「ハードウェアの制約」に縛られる時代から、「最適化技術が差別化要因となる」時代へと完全に移行しました。企業がAIを導入する際、高いGPUコストは常に頭の痛い問題ですが、TurboQuantのような技術の民主化が進めば、より安価なGPU(例えばコンシューマー向けのRTXシリーズなど)でも、エンタープライズ級のLLMを運用することが十分に可能です。
今後は、この技術がどれだけ迅速にOSSライブラリや推論プラットフォームに組み込まれるかが注目されます。私たちは、単にAIを使えるだけではなく、このような「深層技術の潮流」を理解し、最短距離でプロダクトに実装できるチームこそが、これからのAI競争を勝ち残ると確信しています。

結論:進化するアーキテクチャに乗り遅れるな
TurboQuantは単なる「速いアルゴリズム」ではありません。それは、AIの可能性を制約から解き放つための強力なエンジンです。推論エンジンへの統合が進めば、ローカル環境での大規模モデル運用は当たり前になり、AIはより身近で、より速く、より賢い存在へと進化し続けるでしょう。
もしあなたがエンジニアであれば、今すぐ最新の量子化論文や関連リポジトリをチェックしてください。もしビジネスオーナーであれば、インフラコストの劇的な削減とUX向上という二つの面から、この技術の導入ロードマップを検討し始めることを推奨します。進化のスピードは速いですが、追いつく価値は十分にあります。Nexistixはこれからも、こうした「ゲームチェンジャー」となる技術を追い続け、皆様に最速で共有していきます。
さあ、次の推論高速化に向けて、実装の準備を始めましょう。
📣 この記事を読んだ方に特におすすめのアイテムです

NVMe SSD M.2 2280 2TB KIOXIA キオクシア EXCERIA PLUS G4 内蔵型 PCIe Gen5 x4 R:10000MB/s W:8200MB/s 海外リテール LVD10Z002TG8 ◆コ
★★★★★ 5.0(1件のレビュー)
42,999円
LLM推論を高速化!XServer VPSなら、この記事で紹介した技術をサクサク試せます!
LLM推論を高速化!XServer VPSなら、この記事で紹介した技術をサクサク試せます!


コメント